Training
Spending 5 minutes to train Narrator is likely to significantly improve your results. Training just means giving a good/bad verdict to a piece of content that Narrator generated. Narrator saves this verdict, along with an optional reason (you don't have to give a reason, but it's a good idea), and next time it generates content for you it will use those good/bad examples to produce a better response.
Under the covers, Narrator uses Few Shot Prompting to grab a selection of the content examples you marked as good or bad, and automatically passes them to the LLM along with your prompt when you call generate.
Training is done via the train and saveExample functions, and is easy to hook up to the command line, and even easier to hook up to your UI if you use @narrator-ai/react.
Training in the CLI
Let's provide an examplesDir to our Narrator this time:
//this time we configured an examplesDir to tell Narrator where to save good/bad examples
export const narrator = new Narrator({
outputFilename: (docId) => `${docId}.md`,
outputDir: path.join(process.cwd(), "editorial"),
examplesDir: path.join(process.cwd(), "editorial", "examples"),
});
Here's a simple script I use to train Narrator on content that it generates for my post outros GenerationTasks:
//expose the OPENAI_API_KEY
import * as dotenv from "dotenv";
dotenv.config();
import { TaskFactory, narrator } from "@/lib/blog/TaskFactory";
import Posts from "@/lib/blog/Posts";
async function main() {
const taskFactory = new TaskFactory();
const posts = new Posts();
for (const post of posts.publishedPosts) {
await narrator.train(taskFactory.jobForId("post/" + post.slug));
}
}
main()
.catch(console.error)
.then(() => process.exit(0));
That's pretty basic. We're just looping over each published post, creating a GenerationTask (docId + prompt) for each, and passing it in to the train function, which is optimized for CLI-based training. It will generate content and ask you to give it a good/bad rating, or skip it. It will also ask you for a reason why you gave that rating.
Here's the actual shell output from running this:
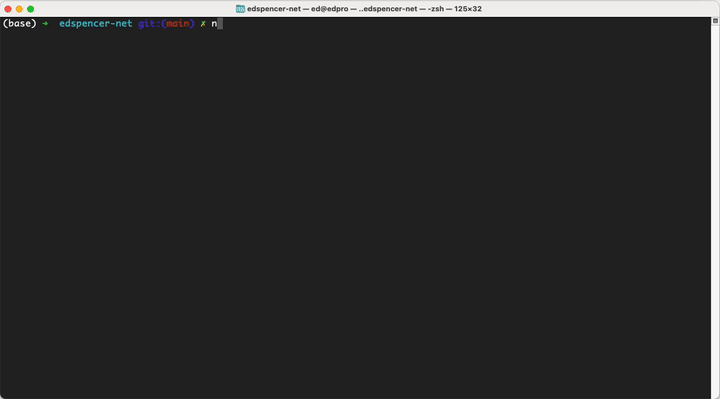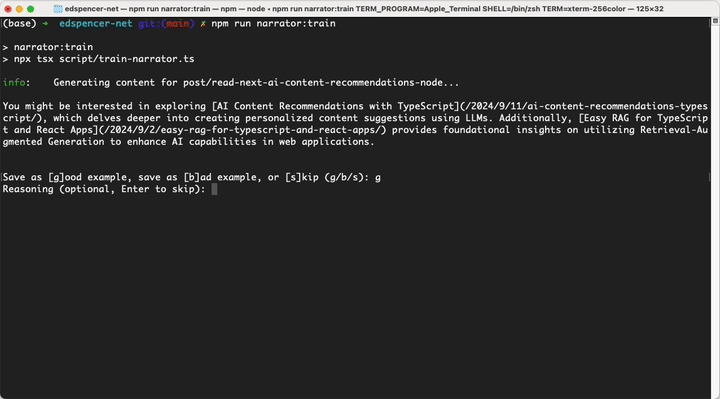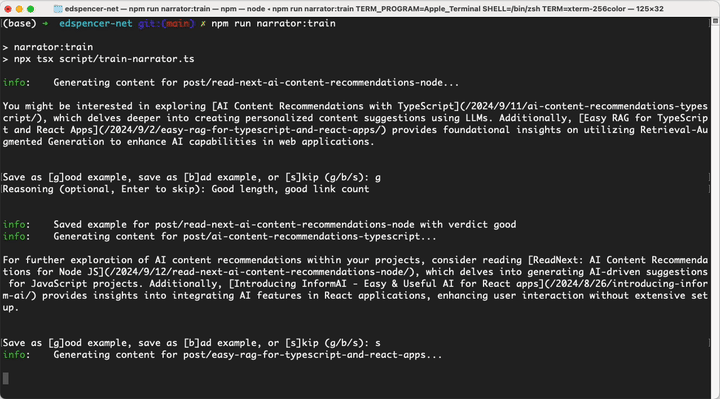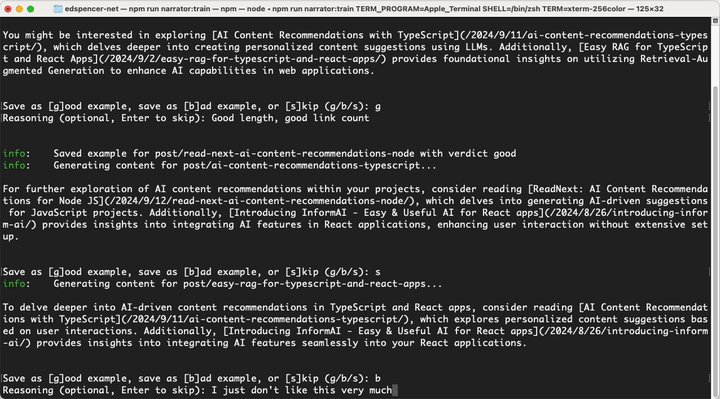
It will keep doing that until it runs out of published posts to generate content for, or you ctrl-c out of it. Note that all this is doing is saving good/bad examples, calling train does generate text, but it won't save it as the actual text for the given docId.
Note that each of the examples above will be saved under the post key - internally, Narrator takes everything before the / in the docId (if there is one) and treats that as a group. Above, we trained by generating content for post/read-next-ai-content-recommendations-node and post/ai-content-recommendations-typescript, and the verdicts and optional reasons we supplied were saved under the post key. Next time we either generate or train on a docId that starts with post/, Narrator will grab some or all of those good/bad examples and pass them to the LLM to tell it what we like and don't like.
The performance of the LLM in generating the type of content you want goes up significantly even after only training on a few examples. You only have to do it once; under the covers the examples are saved as .yml files and should be committed to source control.
Training in the UI
If you are using @narrator-ai/react, you can train Narrator directly in your UI while you're developing. This is perhaps even easier than doing it via the CLI, and has the benefit of showing you the fully rendered content in the actual context it will be shown in inside your UI.
If you set up your Narrator provider like shown above, you can now train directly in your UI by just clicking the thumbs up/down buttons and optionally providing a reason for your selection. The outcome is exactly the same as in the CLI, but this is more fun:
